Core Concepts¶
ZenML consists of the following key components:
Repository¶
A repository is the foundation of all ZenML activity. Every action that can be executed within ZenML has to necessarily take place within a ZenML repository. ZenML repositories are inextricably tied to git.
Datasources¶
Datasources are the heart of any machine learning process and that’s why they are first-class citizens in ZenML. While every pipeline takes one as input, a datasource can also be created independently of a pipeline. At that moment, an immutable snapshot of the data is created, versioned, and tracked in the artifact store and metadata store respectively.
Pipelines¶
An ZenML pipeline is a sequence of tasks that execute in a specific order and yield artifacts. The artifacts are stored within the artifact store and indexed via the metadata store (see below). Each individual task within a pipeline is known as a step. The standard pipelines (like TrainingPipeline) within ZenML are designed to have easy interfaces to add pre-decided steps, with the order also pre-decided. Other sorts of pipelines can be created as well from scratch.
The moment it is run, a pipeline is converted to an immutable, declarative YAML configuration file, stored in the pipelines directory (see below). These YAML files may be persisted within the git repository as well or kept separate.
Steps¶
A step is one part of a ZenML pipeline, that is responsible for one aspect of processing the data. Steps can be thought of as hierarchical: There are broad step types like SplitStep, PreprocesserStep, TrainerStep etc., which defined interfaces for specialized implementations of these concepts.
As an example, let’s look at the TrainerStep. Here is the hierarchy:
BaseTrainerStep
│
└───TensorflowBaseTrainer
│ │
│ └───TensorflowFeedForwardTrainer
│
└───PyTorchBaseTrainer
│
└───PyTorchFeedForwardTrainer
Each layer defines its own special interface that is essentially placeholder functions to override. So, someone looking to create a custom trainer step should subclass the appropriate class based on the user’s requirements.
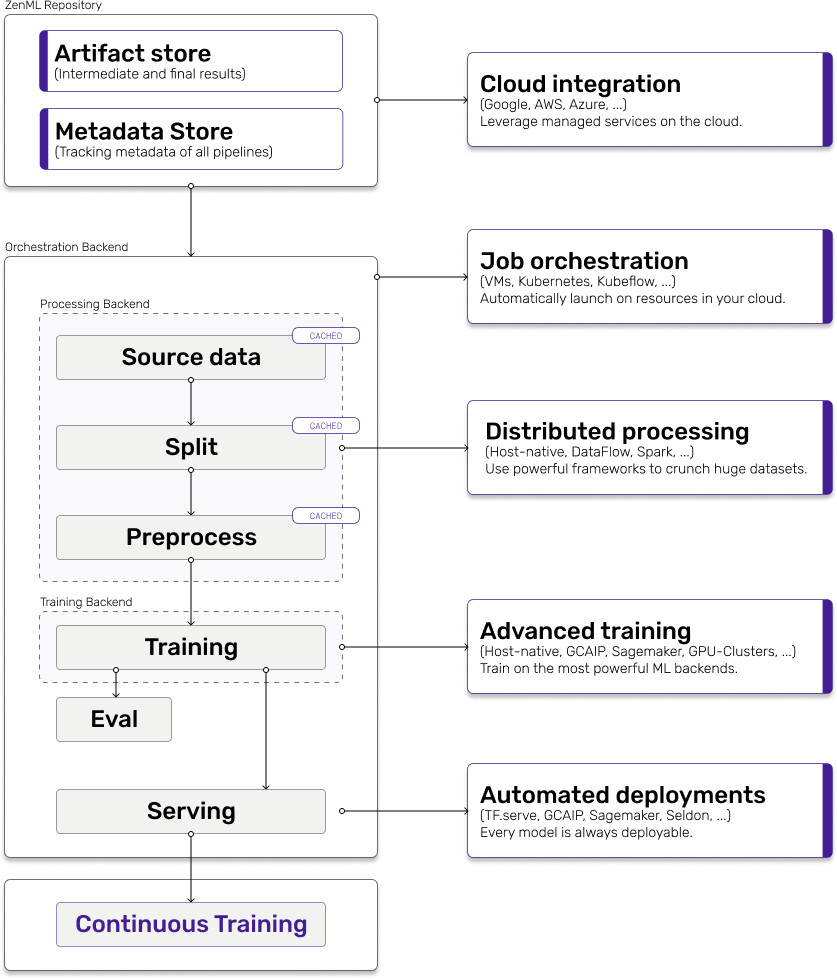
Backends¶
If datasources represent the data you use, and pipelines/steps define the code you use, backends define the configuration and environment with which everything comes together. Backends give the freedom to separate infrastructure from code, which is so crucial in production environments. They define where and how the code runs.
Backends are defined either per pipeline (here they are called OrchestratorBackends), or per step (i.e. ProcessingBackends, TrainingBackends).
Read more about backends here.
Pipelines Directory¶
A pipelines directory is where all the declarative configurations of all pipelines run within a ZenML repository are stored. These declarative configurations are the source of truth for everyone working in the repository and therefore serve as a database to track not only pipelines but steps, datasources, and backends, including all configurations.
Artifact Store¶
Pipelines have steps that produce artifacts. These artifacts are stored in the artifact store. Artifacts themselves can be of many types, such as TFRecords or saved model pickles, depending on what the step produces.
Metadata Store¶
The configuration of each datasource, pipeline, step, backend, and produced artifacts are all tracked within the metadata store. The metadata store is SQL database, and can be sqlite or mysql.
Important considerations¶
Artifact stores and metadata stores can be configured per repository as well as per pipeline. However, only pipelines with the same artifact store and metadata store are comparable, and therefore should not change to maintain the benefits of caching and consistency across pipeline runs.
On a high level, when data is read from a datasource the results are persisted in your artifact store. An orchestration integration reads the data from the artifact store and begins preprocessing - either itself or alternatively on a dedicated processing backend like Google Dataflow. Every pipeline step reads its predecessor’s result artifacts from the artifact store and writes its own result artifacts to the artifact store. Once preprocessing is done, the orchestration begins the training of your model - again either itself or on a dedicated training backend. The trained model will be persisted in the artifact store, and optionally passed on to a serving backend.
A few rules apply:
Every orchestration backend (local, Google Cloud VMs, etc) can run all pipeline steps, including training.
Orchestration backends have a selection of compatible processing backends.
Pipelines can be configured to utilize more powerful processing (e.g. distributed) and training (e.g. Google AI Platform) backends.
A quick example for large data sets makes this clearer. By default, your experiments will run locally. Pipelines on large datasets would be severely bottlenecked, so you can configure Google Dataflow as a processing backend for distributed computation, and Google AI Platform as a training backend.
System design¶
The design choices in ZenML follow the understanding that production-ready model training pipelines need to be immutable, repeatable, discoverable, descriptive, and efficient. ZenML takes care of the orchestration of your pipelines, from sourcing data all the way to continuous training - no matter if it’s running somewhere locally, in an on-premise data center, or in the Cloud.
In different words, ZenML runs your ML code while taking care of the “Operations” for you. It takes care of:
Interfacing between the individual processing steps (splitting, transform, training).
Tracking of intermediate results and metadata
Caching your processing artifacts.
Parallelization of computing tasks.
Ensuring the immutability of your pipelines from data sourcing to model artifacts.
No matter where - Cloud, On-Premise, or locally.
Since production scenarios often look complex, ZenML is built with integrations in mind. ZenML supports an ever-growing range of integrations for processing, training, and serving, and you can always add custom integrations via our extensible interfaces.